
Introduction to BigData
- Hadoop :处理大数据的开源框架
including:
- MapReduce: 处理大数据的program
- HDFS: 文件系统
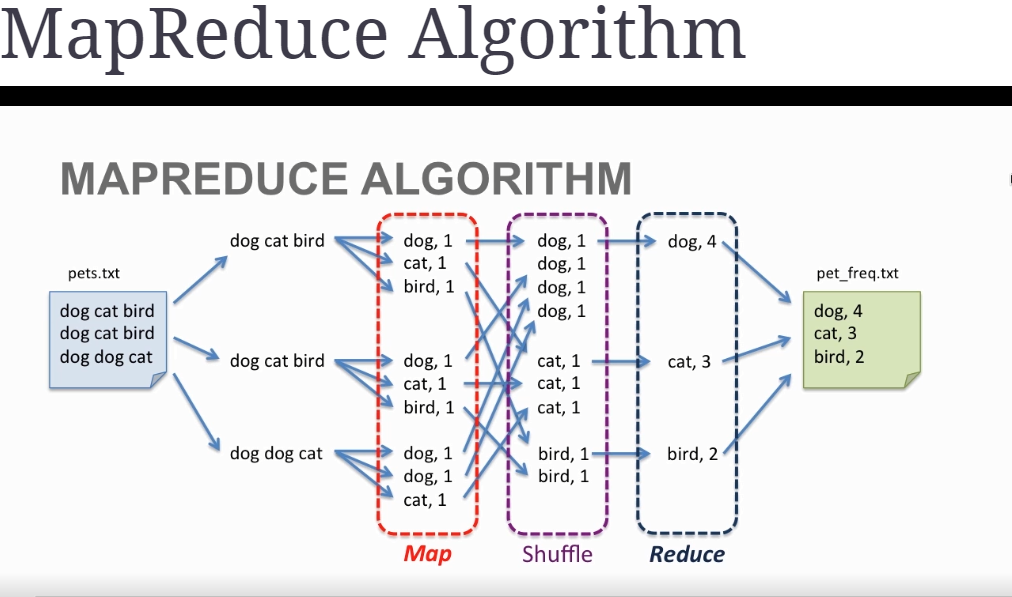
MapReduce: split, map, shuffle, reduce
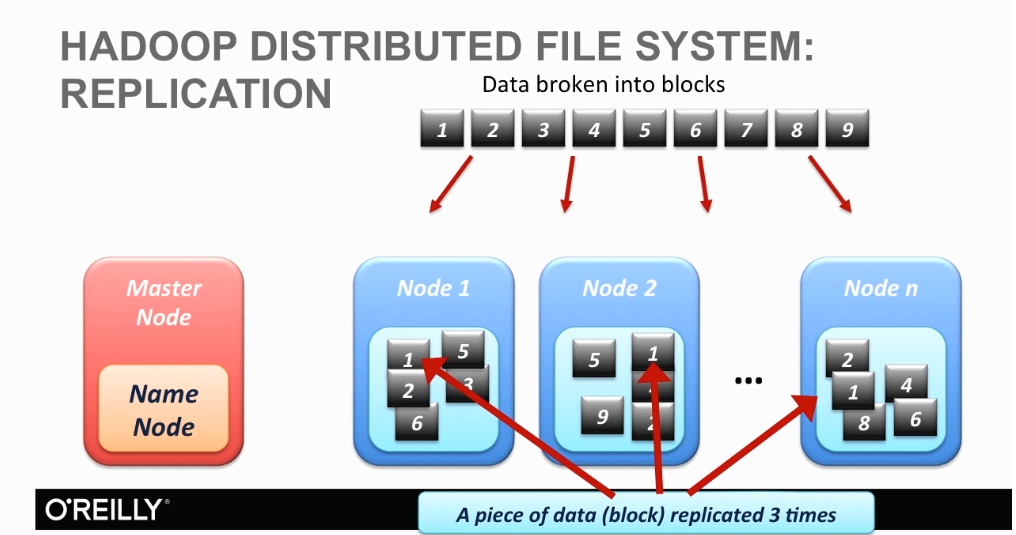
HDFS: 数据被分成多个block, 分布存储在cluser里的多个node, 每一个block默认repicated 3 times
- HDFS block:HDFS上的文件被划分为块大小的多个分块,作为独立的存储单元,称为数据块,默认大小是64MB/128MB。
- HDFS的三个节点:Namenode,Datanode,Secondary Namenode
- Namenode:HDFS的守护进程,用来管理文件系统的命名空间,负责记录文件是如何分割成数据块,以及这些数据块分别被存储到那些数据节点上,它的主要功能是对内存及IO进行集中管理。
- Datanode:文件系统的工作节点,根据需要存储和检索数据块,并且定期向namenode发送他们所存储的块的列表。
- Secondary Namenode:辅助后台程序,与NameNode进行通信,以便定期保存HDFS元数据的快照。
- HDFS resides on top of a native file system(Linux)
- HDFS不适合用在:要求低时间延迟数据访问的应用,存储大量的小文件,多用户写入,任意修改文件。
- HDFS shell commands
- hadoop fs -get /user/hadoop/file
- hadoop fs -put localfile /user/hadoop/hadoopfile
- copyFromLocal
- copyToLocal
How map-reduce tasks running on data nodes?
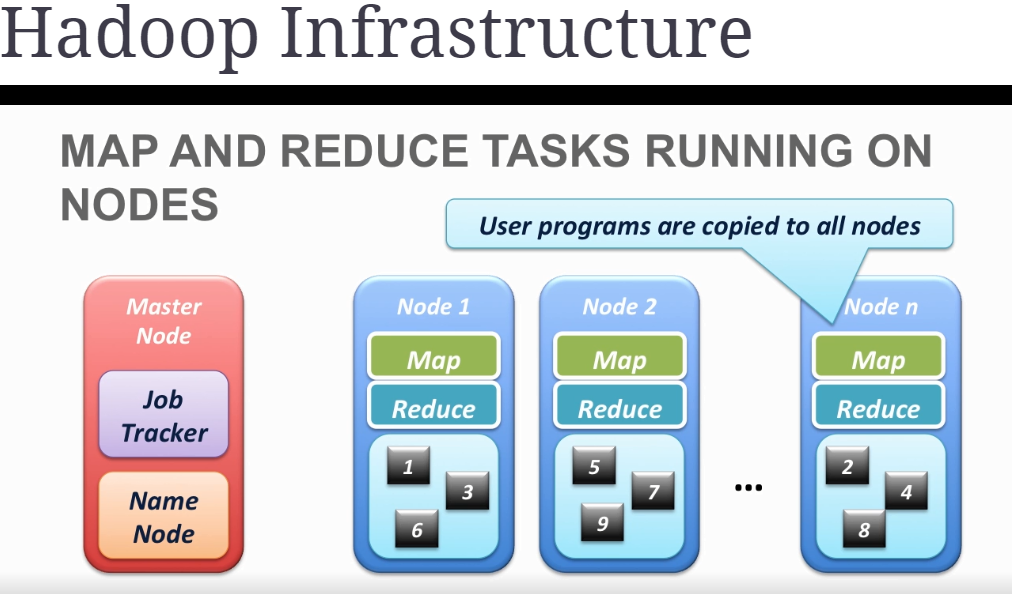
- hadoop send the programme(map-reduce) to data
- hadoop send the programme(map-reduce) to data
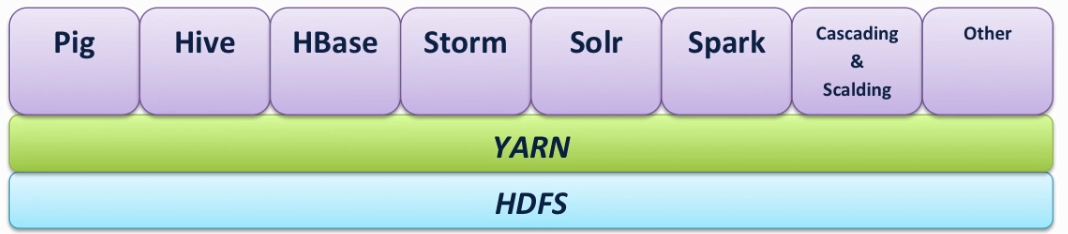
Yarn (Hadoop 2代架构)
在 Hadoop MapReduce (Hadoop 1代架构) 中,JobTracker 具有两种不同的职责:
- 管理集群中的计算资源,这涉及到维护活动节点列表、可用和占用的 map 和 reduce slots 列表,以及依据所选的调度策略将可用 slots 分配给合适的作业和任务
- 协调在集群上运行的所有任务,这涉及到指导 TaskTracker 启动 map 和 reduce 任务,监视任务的执行,重新启动失败的任务,推测性地运行缓慢的任务,计算作业计数器值的总和,等等
- Yarn/MRv2最基本的想法是将原JobTracker的双重职责(集群资源管理和任务协调)分开为两种不同类型的进程来反映。
Yarn/MRv2
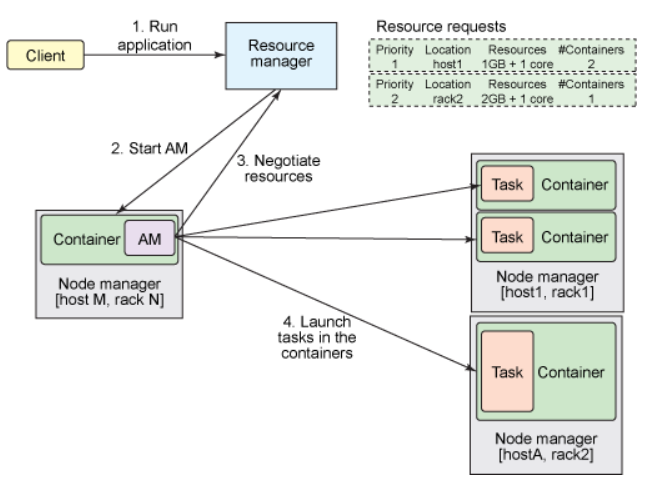
- ResourceManager 代替集群管理器,任何client或者运行着的applicatitonMaster想要运行job或者task都得向RM申请一定的资源
- ApplicationMaster 代替一个专用且短暂的 JobTracker
- NodeManager 代替 TaskTracker
- 一个分布式应用程序代替一个 MapReduce 作业。
Programme for Hadoop could by
- Hive: table mapping? hive query is mapreduce jobs?
- 处理大数据,但是非实时(batch only)
- 不支持update
- Pig:
- 并发的做一些简单结构的数据分析
- ETL ?
- Scalding
- 大数据的并发计算
- 可以访问各种类型数据库
- Hive: table mapping? hive query is mapreduce jobs?
Hadoop Ecosystem including:
- Apache TEZ: 执行引擎
- Hcatalog
- Mahout: machine learing
- Sqoop:关系型数据库
- Flume
- ZoomKeeper
- Hbase
- Built on top of HDFS
- Size>PB
- Data model is simple
- Random 读写
- High speed required
- 不支持Join
- 比Hive要慢
- Spark: 执行引擎
- 比MR快
- In Memory Data
- Flink: 执行引擎
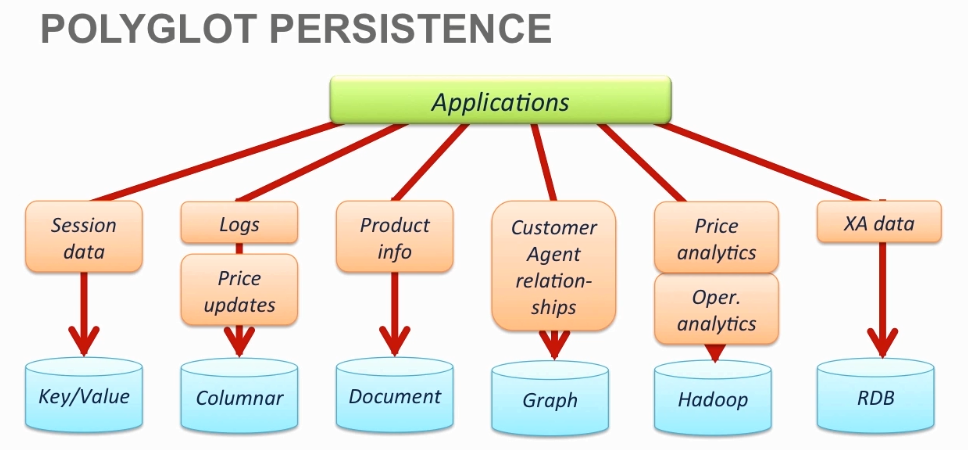
NoSQL 数据库分类
- key/value
- simple data model, json
- session data
- shopping cart
- user profiles
- column family
- high insert volume,logging
- real-time updates
- document
- json, bson, xml
- semi-structured data
- logging
- product/customer info
- web analytics
- graph
- complex graph data:social networks
- highly interconnected data
- key/value
Streaming data 处理系统
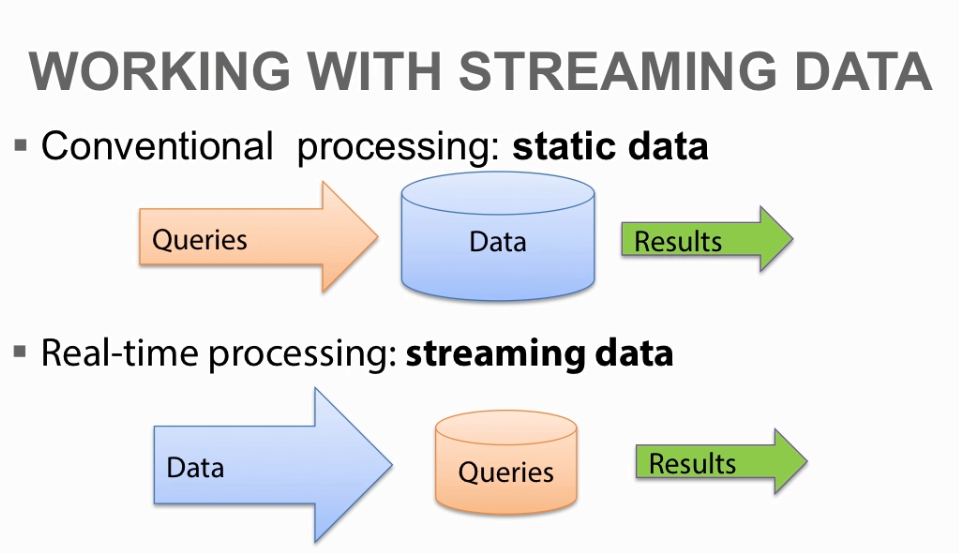
- storm
- spark&flink
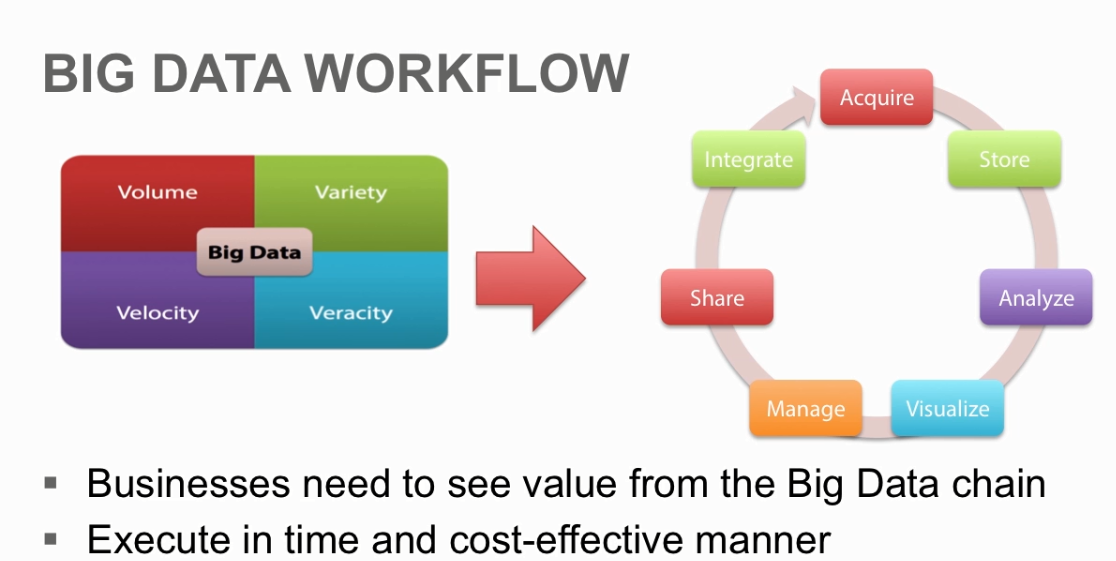
Big Data WorkFlow
Ployglot
Reference
https://www.cnblogs.com/caiyisen/p/7395843.html https://www.ibm.com/developerworks/cn/data/library/bd-yarn-intro/ https://www.cnblogs.com/cxzdy/p/4943159.html

